
今回は、Pythonを使って「Raktenみんなのレビュー」をスクレイプする方法について紹介したいと思います。
今回紹介するソースコードは、こちらのページで紹介した自作のScrape クラスを使っています。
ご自身の環境で動作させたい場合は、このScrapeクラスも合わせてご利用ください。
スクレイプについて更に詳しく知りたい方は、併せてこちらの記事もご一読願います。
概要
今回も関数として作成していて、引数に「Raktenみんなのレビュー」で検索した口コミページのURLを渡すと、その内容を収集してくれるようになっています。
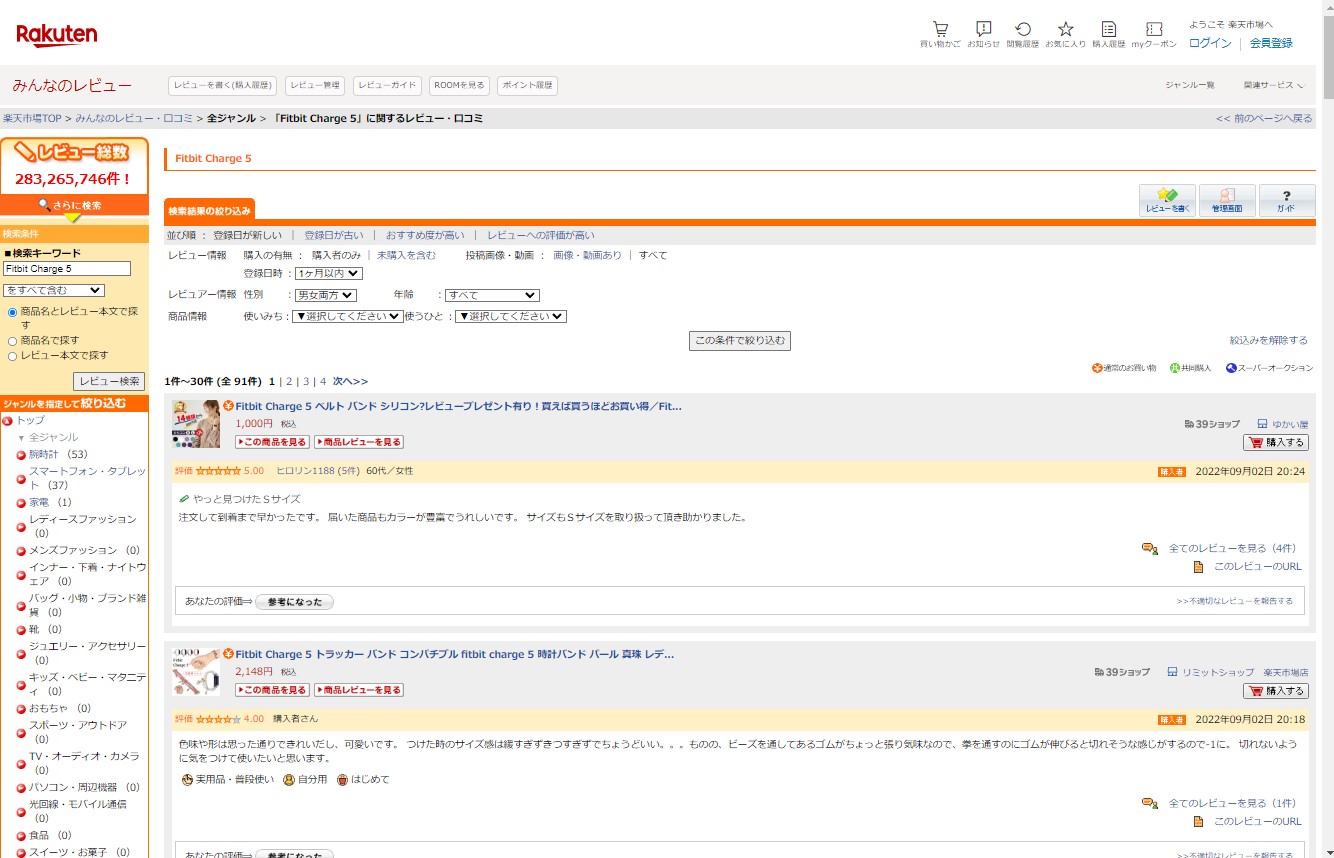
例えば、「Fitbit Charge 5」のレビューを収集したい場合、左の検索キーワード欄で、「Fitbit Charge 5」という商品を検索した結果のページ(その時のURL)が、レビューの収集対象となります。
URLの例:https://review.rakuten.co.jp/search/Fitbit+Charge+5/
関数の内部では、こちらの記事で紹介した自作クラス(Scrape)を呼び出して使っています。


今回は、フィットネストラッカー「FitBit 5」の製品レビューの口コミページを解析して関数を作成しています。
例えばある時期以降の製品レビューの仕様が変更されたりとかの事情で、別の商品だとうまくスクレイプ出来ない可能性もありますが、その点はご了承下さい。
関数のソースは以下の様になります。
出来るだけ多くのコメントを記載しましたので、ざっくり目を通していただければ、おおよそのことが分かるかと思います。
def scrape_rakten(url):
#商品レビューにおける各ページのURLを生成
scr = Scrape(wait=2,max=5)
for n in range(1,1000):
#商品の指定ページのURLを生成
target = f'{url}/-/d0-p{n}/'
print(f'get:{target}')
#ページ内のレビュー記事を一括取得
soup = scr.request(target)
reviews = [ x for x in soup.find_all('table') if '全てのレビューを見る' in x.text and x.text.replace('\n','')[:2] == '評価' ]
print(f'レビュー数:{len(reviews)}')
#ページ内容レビュー記事の内容をループで全て取得
for m in range(len(reviews)):
if '評価' in scr.get_text(reviews[m].find_all('td')[0].find('span')):
comment = scr.get_text(reviews[m].find('font',class_='ratCustomAppearTarget')).replace('\n','')
title = scr.get_text(reviews[m].find_all('font')[1])
star = reviews[m].find_all('td')[0].find('span').text.split()[1]
date = scr.get_text(reviews[m].find_all('font')[0]).replace('\n\u3000','')[:11]
scr.add_df([title,star,date,comment],['title','star','date','comment'],['\n'])
#次のページが存在するかチェック(件数が30未満の場合は最終ページと判断)
if len(reviews) < 30:
break
#CSV出力
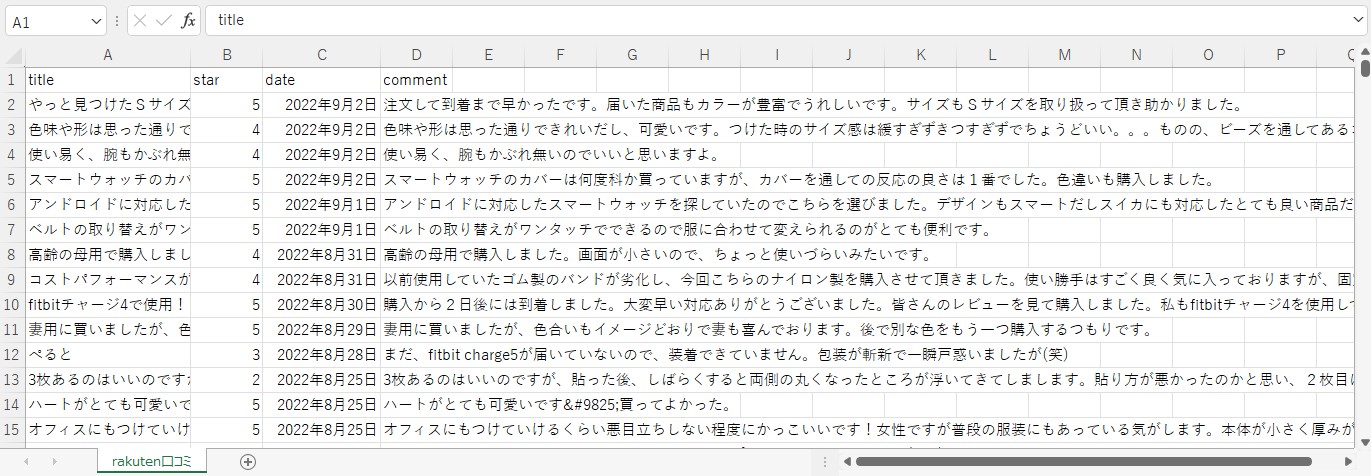
scr.to_csv("p:/rakuten口コミ.csv")
関数の使い方
使い方は簡単で、引数にスクレイプしたい商品のURLを渡すだけでOKです。
scrape_rakten(スクレイプしたいURL)
scrape_rakten('https://review.rakuten.co.jp/search/Fitbit+Charge+5/')
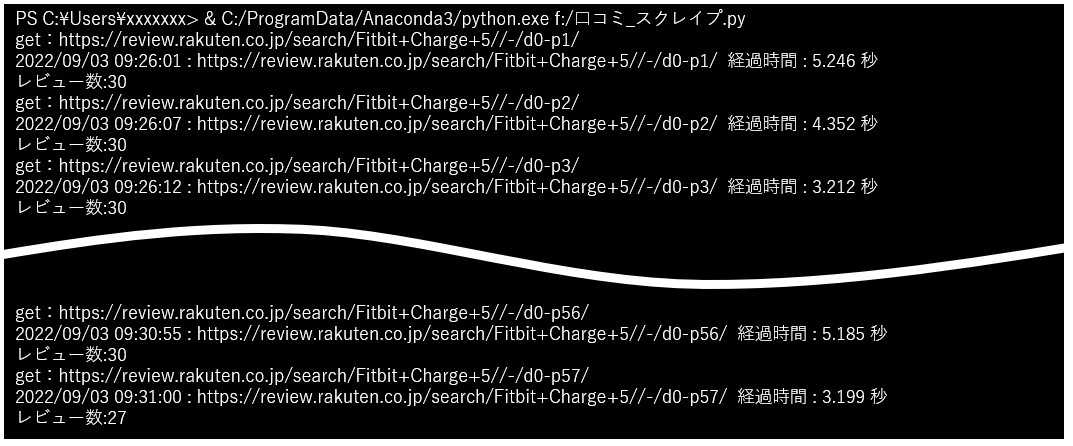
実行中は、途中経過がコンソール上に表示されます。
まとめ
今回は、「Raktenみんなのレビュー」をPythonでスクレイピングする方法について紹介しました。
関数化しているので、コピペしてお使い頂けます。
今回は「Fitbit 5」の検索結果のページを解析してプログラムを作っていますので、別の商品の中には、もしかするとうまくスクレイピング出来ないものがあるかもしれません。
その場合は、ソースのコメントを見ながら、適宜修正して頂ければと思います。
ちなみに、今回のスクレイピングで得たレビューに対して、ワードクラウドや文書要約を行うことも可能です。
ご興味のある方は、下記URLから関連議事をご参照ください。
【実践】PythonでWordCloud(ワードクラウド)しようぜ!
【実践】Python+pysummarizationで文書要約(テキストマイニング)しよう!
【実践】Python+sumyで文書要約(テキストマイニング)しよう!
今回の記事がプログラミングの一助になれば幸いです。