
これまでに、MeCab と janome を使った形態素解析について紹介してきました。
今回は、GiNZAを使った形態素解析について紹介します。
ついでに、ユーザー辞書の登録方法と、解析結果をMeCab形式で出力するための方法についても触れていますので、興味のある方は是非ご一読ください。
GiNZAとは
GiNZAとは、Megagon Labsと国立国語研究所の共同研究によって誕生した自然言語処理用のライブラリで、自然言語処理のフレームワークであるspaCy と、形態素解析機である SudachiPy の2を内部で使っています。
今回の記事では、形態素解析機の部分に焦点を当てています。
GiNZAについては、こちら の記事でもう少し詳しく触れていますので、興味のある方は是非お読みください。
インストール方法
インストールは pip コマンドを使います。
pip install -U ginza ja_ginza
お使いのPCに16GB以上のメモリがあり、更なる精度を求めるのであれば、次のコマンドを実行して下さい。
pip install -U ginza ja_ginza_electra pip install -U ginza https://github.com/megagonlabs/ginza/releases/download/latest/ja_ginza_electra-latest-with-model.tar.gz
形態素解析の方法
GiNZAを使うには、あらかじめ spacy と ginza のインポートが必要です。
import spacy import ginza
使い方は以下の手順になります。
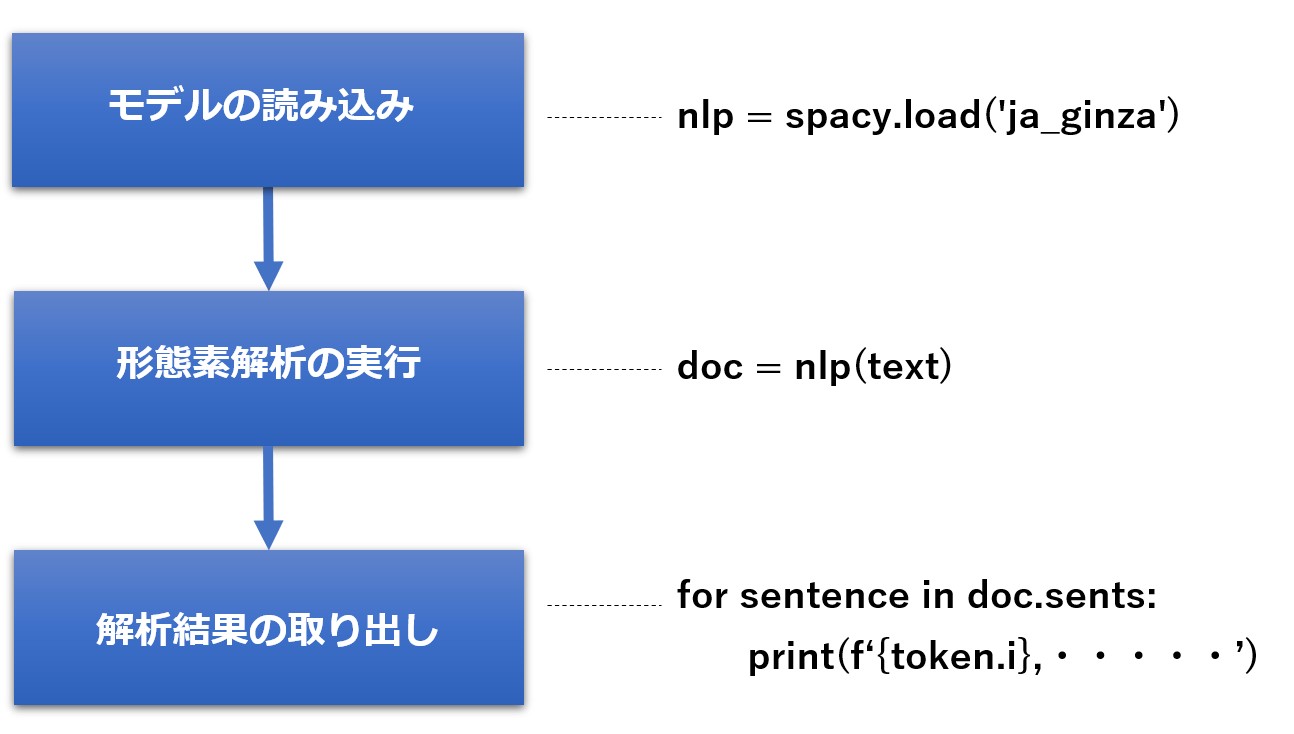
import spacy
import ginza
text = '渋谷で働くデータサイエンティストが新しいPCで処理時間を測った'
nlp = spacy.load('ja_ginza_electra')
doc = nlp(text)
for sentence in doc.sents:
# 形態素解析の実行
for token in sentence:
# 結果を取得
print(f'{token.i}, {token.orth_}, {token.lemma_}, {token.norm_},{token.morph.get("Inflection")},{token.pos_}, {token.tag_}, {token.dep_}, {token.head.i},{token.morph.get("Reading")}')
実行結果は次の通りです。

出力形式は CoNLL-Uフォーマット とのことですが、読んでもよくわかりませんでした。
ほとんどの場合、品詞で分類したいだけなので、左から7番目の項目で判断して下さい。
MeCab互換の出力形式
GiNZAの出力項目が100% MeCabの出力項目と一致はしないのですが、ほぼ項目の並びを合わせる事ができたので、紹介しておきます。
先ほどのプログラムで、 for sentence in doc.sents: ~ 以降を変更しているだけです。
import spacy
import ginza
text = '渋谷で働くデータサイエンティストが新しいPCで処理時間を測った'
#text = '雪の華'
nlp = spacy.load('ja_ginza_electra')
doc = nlp(text)
for sentence in doc.sents:
# 形態素解析の実行
for token in sentence:
# MeCab互換形式
hinshi = token.tag_.split('-') + ['*','*','*','*']
katuyo = (token.morph.get("Inflection")[0].split(';') if token.morph.get("Inflection") != [] else []) + ['*','*']
yomi = (token.morph.get("Reading")[0].split(';') if token.morph.get("Reading") != [] else []) + ['*']
print(f'{token.orth_}\t{hinshi[0]},{hinshi[1]},{hinshi[2]},{hinshi[3]},{katuyo[0]},{katuyo[1]},*,{token.lemma_},{token.orth_},{yomi[0]}')
以下が実行結果です。

ユーザー辞書の登録方法
GiNZAへのユーザー辞書の登録手順は次のようになります。

CSVのフォーマット
形態素解析に SudachiPyを使っているので、こちらの公式ページに辞書として登録可能なCSVの詳細が掲載されています。
ここでは簡単に説明しておきます。
まず、CSVは下記のフォーマットで作成する必要があります。

左連接ID,右連接IDともに、以下の値が推奨されています。
| 普通名詞 | 5146 名詞,普通名詞,一般, , , , *,漢 5133 名詞,普通名詞,サ変可能, , , , *,漢 |
| 固有名詞 | 4786 名詞,固有名詞,一般, , , , *,固 4789 名詞,固有名詞,人名,名, , , ,固 4790 名詞,固有名詞,人名,姓, , , ,固 |
一方、コストについては、名詞類の登録であれば、「5000~9000」が推奨されています。
辞書のビルド
辞書が出来上がったら、次のコマンドで辞書をビルドします。
sudachipy ubuild -s [システム辞書のパス] [作成したcsvファイルのパス]
第一引数はシステム辞書のパスです。
このコマンドを実行したからといって、ユーザー辞書の内容がシステム辞書に追加されるわけではありませんのでご安心ください。
Pythonをどこにインストールしたかによって変わってきますが、私の場合は下記の場所にありました。
C:\ProgramData\Anaconda3\Lib\site-packages\sudachidict_core\resources\system.dic
例えば、Pドライブに GinzaUserDic.csv というファイルを作った場合、次のようになります。
sudachipy ubuild -s C:\ProgramData\Anaconda3\Lib\site-packages\sudachidict_core\resources\system.dic p:\GinzaUserDic.csv
このコマンドによって、カレントドライブに user.dic が生成されます。
ちなみに、出力先や出力辞書名を指定したい場合は、-o オプションで指定可能です。
sudachipy ubuild -s [システム辞書のパス] -0 [出力する辞書のパス] [作成したcsvファイルのパス]
例えば、Pドライブに MyDic.dic という名前で出力したい場合は次のようになります。
sudachipy ubuild -s C:\ProgramData\Anaconda3\Lib\site-packages\sudachidict_core\resources\system.dic -o p\MyDic.dic p:\GinzaUserDic.csv
sudachi.json への追加
私の場合は以下のフォルダにsudachi.jsonがありました。
C:\ProgramData\Anaconda3\Lib\site-packages\sudachipy\resources
ここの sudachi.json の “characterDefinitionFile”:”char.def”, の次に、以下の形式でユーザー辞書のパスを追加します。
“userDic”:ユーザー辞書のパス,
この時、行末尾のカンマを忘れないように。
例えば、Pドライブのuser.dic を追加する場合、次のようになります。
"userDic":["p:\\user.dic"],
Windowsの場合、パスの区切りの¥は2個連ねて¥¥と記述しないとエラーになりますのでご注意ください。

まとめ
今回は GiNZAを使った形態素解析について紹介致しました。
GiNZAの形態素解析速度はMeCabよりも遅いですが、手軽にインストール可能で64BitのPythonに完全対応しているところと、係り受け分析まで一気通貫で行えるところが魅力です。
20億件の学習済みモデルを利用することで、MeCabを超える(たぶん)精度も期待できます。
形態素解析にも種類によって色々な特徴があるので、用途によって使い分けて頂ければと思います。
今回の記事が皆さんの一助になれば幸いです。