
以前、あちら の記事と こちら の記事で形態素解析についての方法を紹介しました。
形態素解析を行うことで、単語の区切りが分りづらい日本語文書から、簡単に品詞を取り出す事ができるようになります。
この結果を集計したり、可視化することで文書全文を読まずとも、おおよそ何が掛かれているのかを把握することができます。
しかし、例えば「サポート」「画質」「良い」「悪い」という4つの単語が取り出された場合、「サーポート」と「画質」のどちらが良くて、どちらが悪いのかが判断つきません。
係り受け解析を行うことで、「良い」は「サポート」と「画質」のどちらに係っているのかが分かるようになり、文書の理解が随分やり安くなります。
今までと同様、今回もクラス化しているので、コピペですぐにお試し頂けるようにしています。
係り受け解析に興味のある方は、是非ご一読ください。
係り受け解析の概要
冒頭でも申しました通り、係り受けとは「文中の言葉同士の関係性」の事です。
以下の様に、品詞の前後関係を分析してくれます。
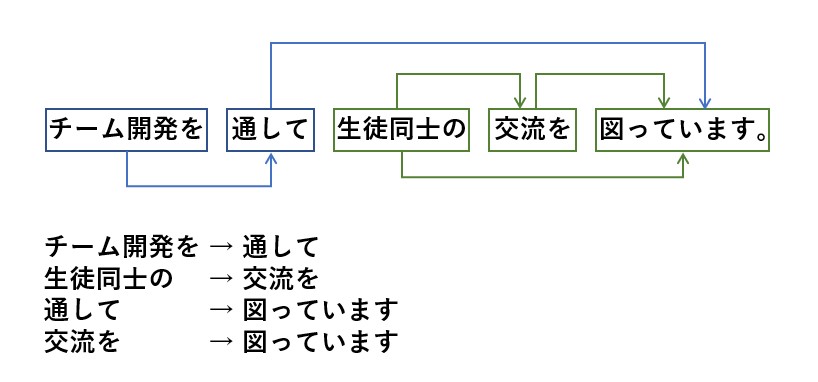
日本語に限らず、文書にはどちらとも解釈できるケースも多々あります。
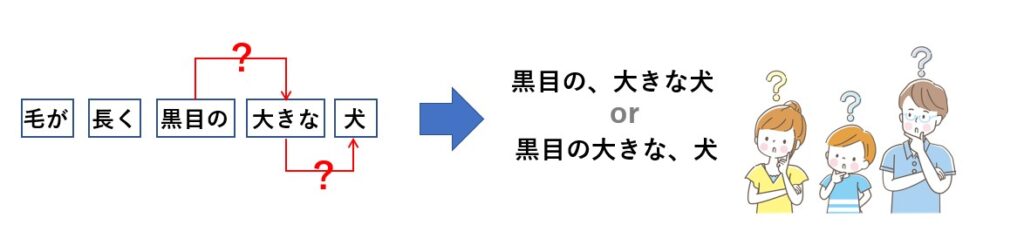
この様な場合も解析はしてくれますが、当然意図した結果が得られないかもしれません。
この辺は人それぞのの解釈が異なるので、最終的に前後の文書を人が見て判断せざるを得ないでしょう。
GiNZAとは
GiNZAとは、リクルートのグループ企業であるMegagon Labsと国立国語研究所の共同研究によって誕生した自然言語処理用のライブラリです。
欧米で使用されている自然言語処理ライブラリ「spaCy」を日本語に対応させたものであり、以下の特徴があります。
- 形態素解析、係り受け解析が可能
- 64BitのPythonに対応
- Python だけでなく、コマンドラインでの処理も可能
- pip installで完了する簡単インストール
- GPUに対応
- オープンソース(MTIランセンス)
係り受け解析では Mecab と組み合わせて使う CaboCha が有名ですが、Mecab は公式的に32bit 版しか存在しないので、必然的にCaboCha を利用する場合は 32bit版Pythonを使わなければなりません。
この点、GiNZAは6bit版Pythonに対応しているので、扱いやすくなっています。
GiNZAの構造
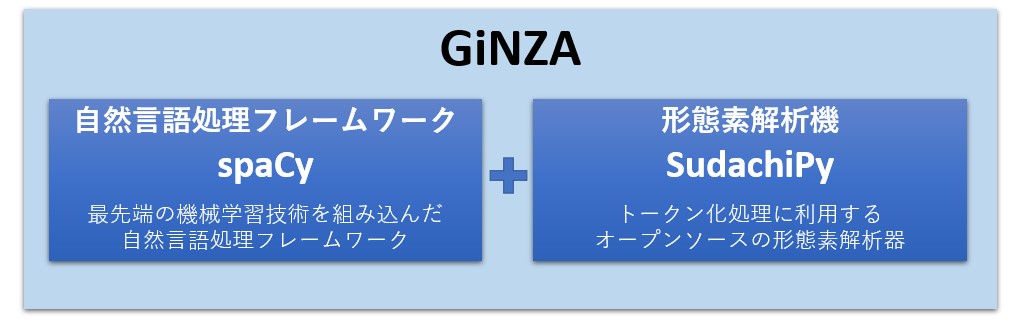
GiNZAは 自然言語処理のフレームワークであるspaCy と 形態素解析機である SudachiPy の2つで構成されています。
つまり、係り受け解析を実行する前に、SudachiPy で形態素解析が行われているのです。
GiNZAの詳細説明
GiNZAの詳細(メソッドの仕様等)については、以下のページに書かれていますので、必要に応じてご参照下さい。

インストール方法
GiNZAは pip コマンドでインストール可能ですが、パラメータの違いにより2通りがあります。
<インストール方法1>
pip install -U ginza ja_ginza_electra でインストールする場合、GiNZAのライブラリがインストールされるだけで、この時点で辞書はインストールされません。
辞書は、初回実行時にダウンロードされます。
<インストール方法2>
pip install -U ginza https://github.com/megag~中略~l.tar.gz でインストールする場合、この時点で辞書も纏めてダウンロードされるので、初回実行時に待たされることはありません。
#インストール方法1 pip install -U ginza ja_ginza_electra #インストール方法2 pip install -U ginza https://github.com/megagonlabs/ginza/releases/download/latest/ja_ginza_electra-latest-with-model.tar.gz
係り受け解析の実行手順
手順は以下の通りです。

係り受け解析する場合、ginza.bunsetu_spans と ginza.bunsetu_phrase_spansの2通りの指定方法があります。
ginza.bunsetu_spans は、係り付け結果が文節で返されます。
例えば、「図っています」の場合は、そのまま「図っています」が返されます。
一方、ginza.bunsetu_phrase_spans は、係り付け結果が主辞で返されます。
主辞とは「文節で一番重要な単語」の事で、「図っています」は「図っ」として返されます。
下記は、必要なライブラリのimportを含んだサンプルです。
import spacy
import ginza
text = 'チーム開発を通して生徒同士の交流を図っています。'
nlp = spacy.load("ja_ginza_electra")
doc = nlp(text)
print('---- bunsetu_spans ----')
for span in ginza.bunsetu_spans(doc):
for token in span.lefts:
print(f'{token} : {str(ginza.bunsetu_span(token))} → {str(span)}')
print('---- bunsetu_phrase_spans (主辞) ----')
for span in ginza.bunsetu_phrase_spans(doc):
for token in span.lefts:
print(f'{token} : {str(ginza.bunsetu_span(token))} → {str(span)}')
結果は次の様になります。

係り受け解析クラスについて
では、さっそく自作した感情分析クラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
クラスの概要
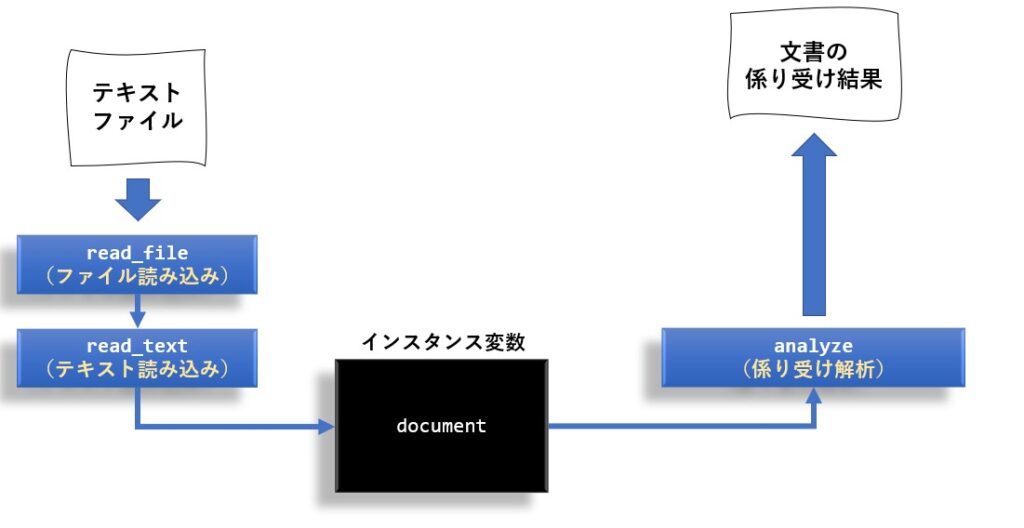
クラス名は DependencyAnalysis にしました。
また、クラスの構造は感情分析や文書要約と合わせていますので、以下の様になっています。
リファレンス
メソッドはコンストラクタ含めて3つです。
| 機能 | メソッド仕様 | 戻り値 |
|---|---|---|
| コンストラクタ | __init__() | |
| ファイルの読み込み | read_file( filename, #入力ファイル名 encoding=’utf-8′ #エンコード名 ) |
なし |
| テキストの読み込み | read_text( text #入力テキスト ) |
なし |
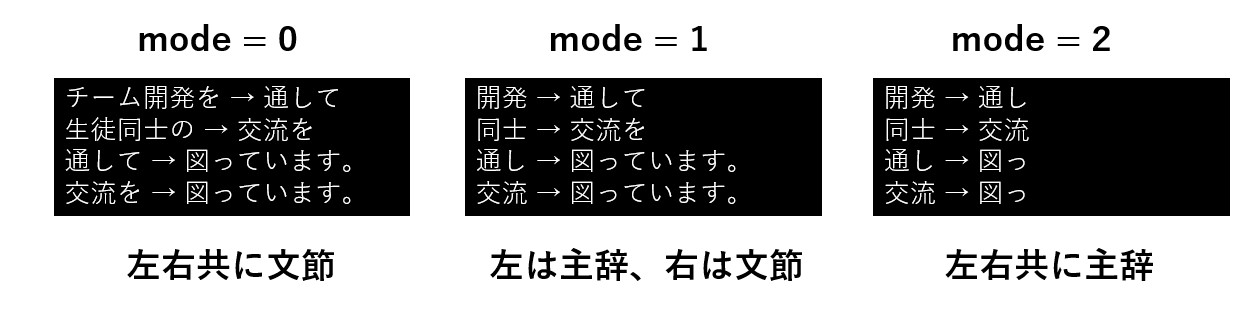
| 係り受け解析の実行 | analyze( text = None, #入力テキスト mode = 0 #動作モード ) |
[ (係り受け元1,係り受け先1), (係り受け元2,係り受け先2), ・・・・・ ] |
analyze メソッドの引数と戻り値
analyze の第一引数に解析したいテキストを指定すると、read_file や read_test で読み込んだテキストは無視され、第一引数のテキストが解析されます。
analyze の 第2引数は動作モードであり、mode は0~2が指定できます。
以下は mode の値に応じた結果の例です。
使い方
使い方は2通りありますが、次の順番にメソッドを呼ぶだけでOKです。

以下に実際のサンプルを掲載しておきます。
dep = DependencyAnalysis()
res = dep.analyze('チーム開発を通して生徒同士の交流を図っています。')
for r in res:
print(f'{r[0]} → {r[1]}')
実行結果は次の様になりました。

ソースコード
それでは、最後にクラスの全ソースコードを紹介しておきます。
import spacy
import ginza
import codecs
class DependencyAnalysis:
def __init__(self):
"""
コンストラクタ
"""
self.nlp = spacy.load("ja_ginza_electra")
self.document = None
def read_file(self,filename,encoding='utf-8'):
'''
ファイルの読み込み
Parameters:
--------
filename : str 分析対象のファイル名
'''
with codecs.open(filename,'r',encoding,'ignore') as f:
self.read_text(f.read())
def read_text(self,text):
'''
テキストの読み込み
Parameters:
--------
text : str 分析対象のテキスト
'''
self.document = text
def analyze(self,text = None,mode = 0):
'''
係り受け結果を主辞(文節で一番重要な単語)で出力
Parameters:
--------
mode : int 0=通常の係り受け 1:係り受けされる側(左)のみに主辞を適用 2: 両方に主辞を適用
'''
ret = []
# mode が 1以下の場合、通常の係り受け関数、2の場合は主辞の関数を使用する
func = ginza.bunsetu_spans if mode <= 1 else ginza.bunsetu_phrase_spans
# 引数があればそれを、Noneの場合はインスタンス変数の self.textを使う
doc = self.nlp(self.document if text == None else text)
# 文書から一文を取り出す
for sentence in doc.sents:
# 係り受けの関数を適用
for span in func(sentence):
# 係り受け解析結果を取り出す
for token in span.lefts:
# modeが 1 の場合のみ、係り受け元を文節として取り出す。(例 mode=0 or 2:交流を mode=1:交流)
key = token if mode >= 1 else ginza.bunsetu_span(token)
# 結果を辞書に登録
ret.append((str(key),str(span)))
return ret
まとめ
今回はGiNZAという自然言語処理ライブラリを用いて、係り付け解析を行ってみました。
係り付け解析の実行速度はMeCab+CaboChaの方が速いという評価もあるようですが、GiNZAはインストールが簡単で、64bitのPython環境で動作するなど、とても魅力的です。
Amazonや価格コムの口コミから全体の評価を推測しようとした場合、単純な形態素解析やワードクラウドでは判断しづらい単語の関連が分かるので、今まで以上に内容が把握し易くなると思います。
とりあえず係り受け解析を手軽に試してみたいという方は、是非ソースコードをコピペしてお試しください。
この記事が皆様の一助になれば幸いです。