
NEologd の辞書には、映画のタイトルや人名、トレンドのキーワードなど、様々な固有名詞が登録され、日々更新されています。
そこで、それを GiNZAの形態素解析で使ってみようと思い、変換用のプログラムを作りました。
もし私と同じことを考えている方がいらっしゃったら、この記事がお役に立つと思います。
前提知識
この記事を読まれている方は当然、NEologd と GiNZAについて既にご存じだと思いますが、過去の記事でダウンロード方法や使い方などを詳しく紹介していますので、必要に応じてご一読ください。


NEologdとGiNZAにおける辞書項目の対応
両者の辞書フォーマットを比較したところ、以下のように対応付けが出来ました。
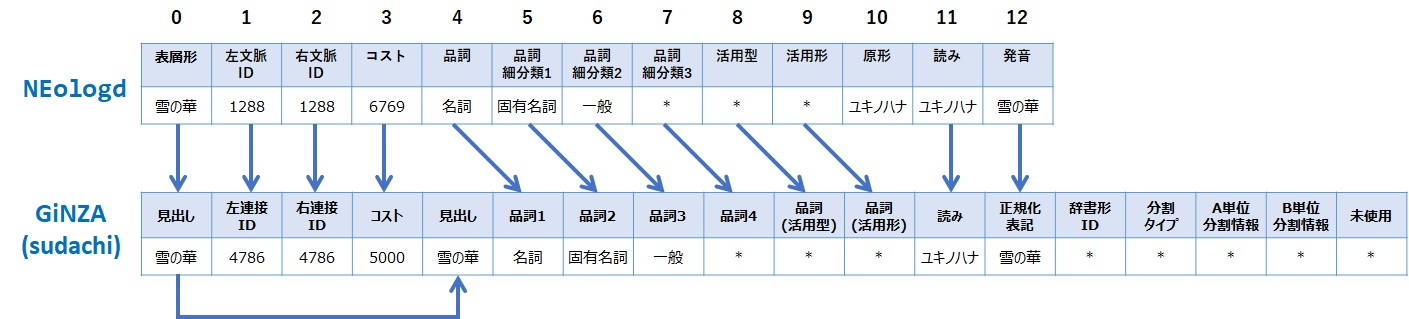
単純に NEologdの辞書を1行ずつ読み込んで、GiNAZ(実際はSudachi)の辞書形式に変えて出力してあげれば事が足りそうです。
ただ、少し問題となるのが左接続ID,右接続ID、コストの3点です。
sudachi の 公式ページ では、以下のように推奨されています。

あくまでも推奨なので、NEologdの左文脈ID、右文脈ID、コストをそのまま代入してもよいのですが、一応考慮することにしました。
作成したクラスの解説
今回は、NeoToSudach という名前でクラスを作成しています。
関数にしようかと思ったのですが、左右の接続IDの算出を入れるとメインのソースコードが長くなりそうなので、クラスにしました。
したがって、クラス丸ごとコピペしていただければ使えます。
使い方
クラスのインスタンスを生成し、convメソッドに NEologdの辞書CSVファイルのパスと、変換後のCSVのパスをひきすうとして渡すだけです。
nts = NeoToSudach()
nts.conv('p:/test.csv','p:/res.csv')
ソースコード
以下はクラスのソースコードになります。
左右の接続IDを求めるメソッド(get_lid,get_rid)は、品詞から推奨値を算出してはいますが、NEologdとGiNZAでは微妙に品詞の表現(NEeologdだと「左辺接続」だが、GiNZAでは「左辺可能」と表現)が異なるため、気休め程度に考えておいてください。
もしかすると、わざわざ算出せずそのまま入れた方がよいのかもしれません。
class NeoToSudach:
'''
==================================================
NEologd 辞書CSV⇒ GiNZA(sudachi)辞書CSV変換クラス
==================================================
'''
def conv(self,input_csv,output_csv):
'''
辞書ファイル変換
Parameters
----------
input_csv str: 変換元CSVのパス
output_csv str: 出力先CSVのパス
'''
#出力先の項目を格納するための箱(リスト)を準備
res = ['*' for x in range(18)]
#出力先を書き込みモードでオープン
with open(output_csv,'w',encoding='utf-8') as wf:
#変換元ファイルを参照モードでオープン
with open(input_csv,'r',encoding='utf-8') as rf:
#1行取得
for line in rf:
#処理中の行を表示
print(line)
#カンマで分解
items = line.replace('\n','').split(',')
#出力先の箱に変換元の項目を移送
res[0] = items[0] #見出し(TRIE 用)
res[1] = self.get_lid(items) #左接続ID
res[2] = self.get_rid(items) #右接続ID
res[3] = items[3] #コスト
res[4] = items[0] #見出し(解析結果表示用)
res[5] = items[4] #品詞1
res[6] = items[5] #品詞2
res[7] = items[6] #品詞3
res[8] = '*' #品詞4
res[9] = '*' #品詞(活用型)
res[10] = '*' #品詞(活用形)
res[11] = items[11] #読み
res[12] = items[12] #正規化表現
res[13] = '*' #辞書形ID
res[14] = '*' #分割タイプ
res[15] = '*' #A単位分割情報
res[16] = '*' #B単位分割情報
res[17] = '*' #未使用
#出力先に1行書き込み
wf.write(','.join(res) + '\n')
def get_lid(self,items):
'''
左接続IDを算出する
Parameters:
------------
imte [str] : 項目のリスト
'''
if(items[4] == '名詞' and items[5] == '普通名詞' and items[6] == '一般'):
return '5146'
if(items[4] == '名詞' and items[5][:2] == 'サ変'):
return '5133'
return items[1]
def get_rid(self,items):
'''
右接続IDを算出する
Parameters:
------------
imte [str] : 項目のリスト
'''
if(items[4] == '名詞' and items[5] == '固有名詞' and items[6] == '一般'):
return '4786'
if(items[4] == '名詞' and items[5] == '固有名詞' and items[6] == '人名'):
return '4789'
return items[2]
変換結果のサンプル
変換した結果は次のようになります。

まとめ
NEologd の辞書に登録されている固有名詞はMeCab用なので、GiNZAの形態素解析で使う場合はsudachi の辞書形式に変換しなければなりません。
今回は、NEologd の辞書CSVを sudachi 用の辞書にフォーマット変換するための方法と、自作クラスについて紹介いたしました。
ソースコードにはコメントを入れていますので、あとは皆さんのお好きなように修正していただければと思います。