
今回は、Pythonを使って価格COMのレビューをスクレイプする方法について紹介したいと思います。
今回紹介するソースコードは、こちらのページで紹介した自作のScrape クラスを使っていますので、ご自身の環境で動作させたい場合は、Scrapeクラスも合わせてご利用ください。
また、スクレイプについて詳しく知りたい方は、併せてこちらの記事もご一読ください。
概要
今回も関数として作成しており、引数に価格COM の商品レビューのURLを渡すと、レビュー内容を収集してくれるようになっています。
URLの例:https://review.kakaku.com/review/J0000037949/#tab’
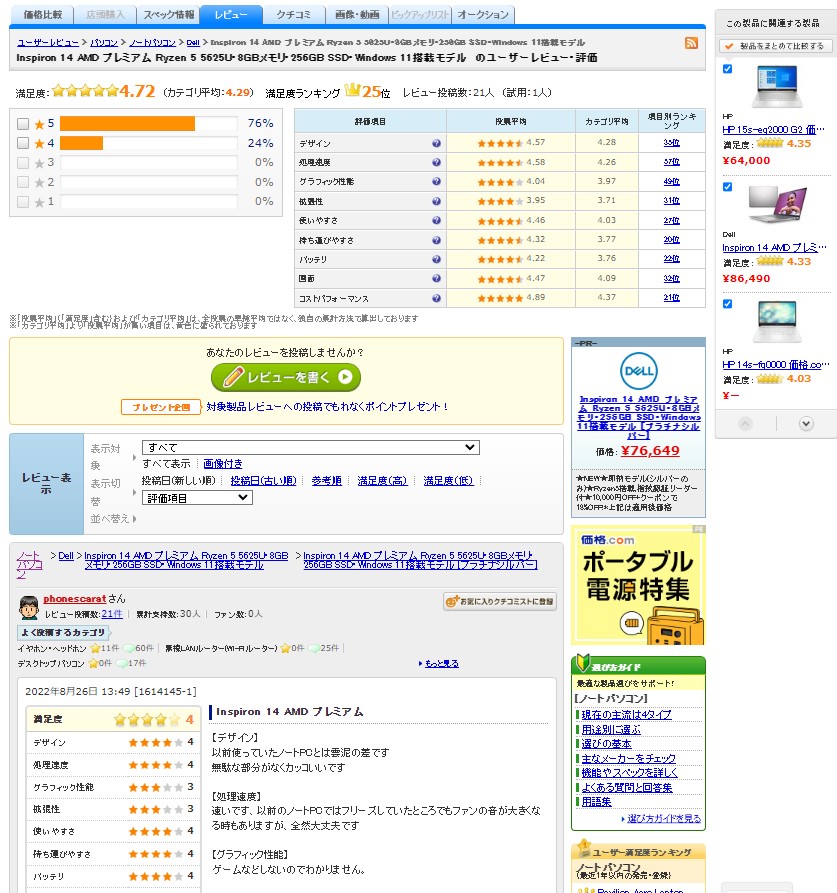
関数内部では、こちらの記事で紹介した自作クラス(Scrape)を呼び出しています。


今回、私が解析したレビューはノートPCの製品レビューであるため、別の商品だとうまくスクレイプ出来ない可能性があります。
また、価格COM のページの仕様が変わった場合も同様ですので、その点はあらかじめご了承ください。
関数のソースは以下の様になります。
出来るだけ多くのコメントを記載しましたので、ざっくり目を通していただければ、おおよそのことが分かるかと思います。
def scrape_kakaku(url):
scr = Scrape(wait=2,max=5)
#レビューのURLから商品IDの手前までを取り出す
url = url[:url.find('#tab')]
for n in range(1,1000):
#商品の指定ページのURLを生成
target = url+f'?Page={n}#tab'
print(f'get:{target}')
#レビューページの取得
soup = scr.request(target)
#ページ内のレビュー記事を一括取得
reviews = soup.find_all('div',class_='revMainClmWrap')
#ページ内のすべてと評価を一括取得
evals = soup.find_all('div',class_='reviewBoxWtInner')
print(f'レビュー数:{len(reviews)}')
#ページ内の全てのレビューをループで取り出す
for review,eval in zip(reviews,evals):
#レビューのタイトルを取得
title = scr.get_text(review.find('div',class_='reviewTitle'))
#レビューの内容を取得
comment = scr.get_text(review.find('p',class_='revEntryCont')).replace('<br>','')
#満足度(デザイン、処理速度、グラフィック性能、拡張性、・・・・・の値を取得
tables = eval.find_all('table')
star = scr.get_text(tables[0].find('td'))
date = scr.get_text(eval.find('p',class_='entryDate clearfix'))
date = date[:date.find('日')+1]
ths = tables[1].find_all('th')
tds = tables[1].find_all('td')
columns = ['title','star','date','comment']
values = [title,star,date,comment]
for th,td in zip(ths,tds):
columns.append(th.text)
values.append(td.text)
#DataFrameに登録
scr.add_df(values,columns,['<br>'])
#ページ内のレビュー数が15未満なら、最後のページと判断してループを抜ける
if len(reviews) < 15:
break
#スクレイプ結果をCSVに出力
scr.to_csv("p:/価格com口コミ.csv")
関数の使い方
使い方は簡単で、引数にスクレイプしたい商品のURLを渡すだけです。
scrape_kakaku(スクレイプしたいURL)
scrape_kakaku('https://review.kakaku.com/review/J0000037949/#tab')
下記は、スクレイピングした結果のCSVをEXCELで開いた画面です。
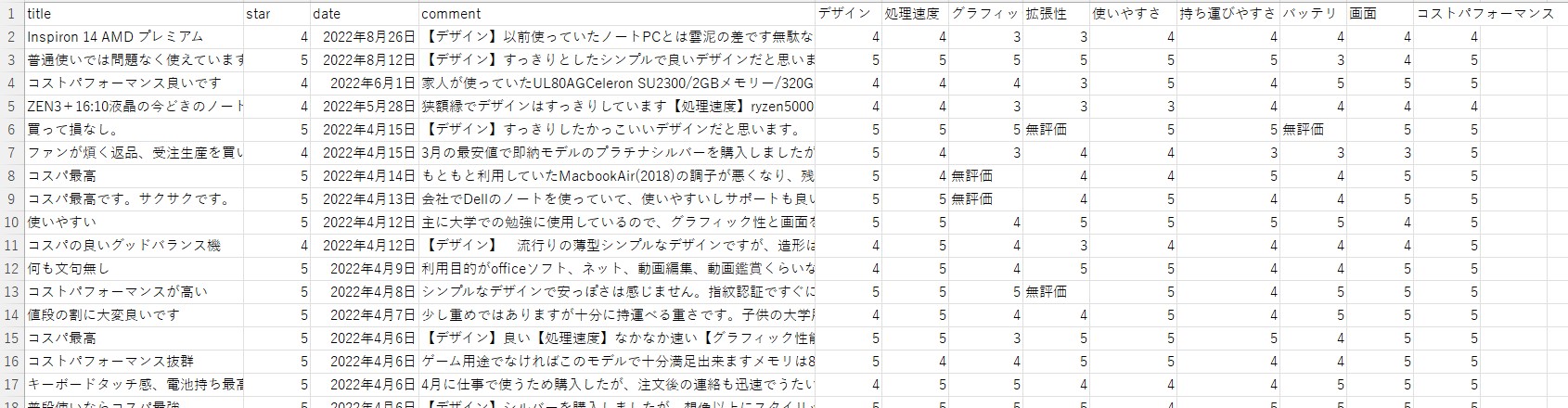
まとめ
今回は、価格COMのレビューをPythonでスクレイピングする方法について紹介しました。
関数化しているので、コピペしてお使い下さい。
尚、今回はノートPCについてのスクレイピングであり、それ以外の商品は確認出来ていませんが、ご了承ください。
途中でエラーになった場合は、ソースのコメントを見ながら、適宜修正して頂ければと思います。
今回のスクレイピングで得たレビューに対して、ワードクラウドや文書要約がしたい場合は、下記URLから関連議事をご参照ください。
【実践】PythonでWordCloud(ワードクラウド)しようぜ!
【実践】Python+pysummarizationで文書要約(テキストマイニング)しよう!
【実践】Python+sumyで文書要約(テキストマイニング)しよう!
今回の記事が皆様のプログラミングの一助になれば幸いです。